Man who ended up spending £700m on two pizzas worth £25 spoke out about decision years later
The Florida-based software engineer traded 10,000 Bitcoin—worth roughly £25 at the time—for two Papa John’s pizzas.
In May 2010, Laszlo Hanyecz made history by completing the first-ever real-world purchase using Bitcoin.
The Florida-based software engineer traded 10,000 Bitcoin – worth roughly £25 at the time – for two Papa John’s pizzas.
It was a transaction that put cryptocurrency on the map. Fast forward to today, and those two pizzas have skyrocketed in value to over £700 million, cementing their place in financial folklore.
But how does Hanyecz feel about what’s now regarded as one of the most infamous purchases in history?
“I don’t regret it,” Hanyecz said in a recent interview. “I think it’s great that I got to be part of the early history of Bitcoin in that way. People know about the pizza. Everyone can kind of relate to that and be like, ‘Oh my God, you spent all of that money!'”
At the time of the transaction, Bitcoin was still in its infancy. Hanyecz, one of the earliest contributors to Bitcoin’s software, had even developed a program allowing users to mine cryptocurrency with their computer’s graphics cards.
Keen to test the real-world usability of Bitcoin, he posted on a crypto forum offering to trade 10,000 coins for pizza. Four days later, he connected with Jeremy Sturdivant, who made the purchase on his behalf and delivered the pizzas.
Laszlo Hanyecz made history (60 Minutes Overtime/YouTube)
Hanyecz proudly shared photos of the pizzas online, unaware of the legacy he was creating. What began as a quirky experiment in digital currency would later become a cultural phenomenon, with May 22 now celebrated annually as ‘Bitcoin Pizza Day’.
While Hanyecz’s payment drew curiosity at the time, it gained widespread attention as Bitcoin’s value began to soar.
In 2023, Bitcoin surpassed $100,000 per coin, turning his two pizzas into a billion-dollar meal.
But Hanyecz remains philosophical about the financial implications. “It’s not about the money,” he explained. “It was about proving that Bitcoin could work as a medium of exchange. That was the whole point.”
Hanyecz’s transition also paved the way for Bitcoin’s adoption as a legitimate payment method. Today, companies like Starbucks, Subway, and even Pizza Hut in certain regions accept cryptocurrency.
“I’m happy to have been part of something so meaningful,” Hanyecz said. “Sure, people laugh about the pizzas, but it’s also a reminder of how far Bitcoin has come since those early days.”
It was one very expensive pizza (Getty Stock Image)
In more recent times, following Donald Trump’s presidential election win, promising more crypto-friendly regulations, the value of Bitcoin has reached a record high.
Stocks and shares, generally, have also soared, while some of the big tech firms have taken a slight hit.
For example, in May 2010, Bitcoin was valued at around £0.003, based on early exchange rates, so a £10 investment would have been bought approximately 3,333 BTC.
So at today’s price of £72,000 per Bitcoin, 3,333 BTC would be worth a whopping £239,976,000 at the time of writing.
People left frustrated after not being able to see terrifying woman in viral photo
This optical illusion might be the toughest one yet
People have been left frustrated about not being able to spot the terrifying woman in a viral photo.
I mean, it’s pretty f**king annoying when it feels like everyone else is discussing something you can’t even see.
It’s like a total FOMO mixed up with irritation and then a kind of existential disappointment that there’s something wrong with you – especially when people are banging on that it’s ‘so obvious’.
Optical illusions always seem to divide people on social media, with some getting it straight away while the rest of us scratch our heads and stare blankly.
So, to keep your ego protected let’s warm up with one:
This viral terrifying woman one really will put your eyesight to test but perhaps not in the way you’re expecting.
At first glance, the image seems wholesome – a blonde little girl and her brunette friend sitting alongside each other in some kind of woodland.
The fair-haired youngster’s face is turned to look at her pal, while the other child seems to be staring at the floor.
Just two little girls having a bit of a giggle while they sit in the woods. Cute, right?
Well, it is until you have a proper look. If you have anything less than 20/20 vision, you might have got a fright while scrolling past this post online.
See anything? (X)
It seems those of us cursed to wear glasses or contact lenses for the rest of our lives have a bit of a strange superpower when it comes to this snap.
People who have blurred vision when not using any visual aids are able to see a third face in the photo.
Some X users claim to have spotted it instantly, but others were dumbfounded and didn’t know where they were supposed to be looking.
One said: “Well, that was nightmare fuel. Thanks for the loss of sleep I’ll be having.”
Another wrote: “Apparently I’m not as blind as I thought. I see two children. No matter what I do with my phone or the amount of squinting!”
A third added: “Seriously, what am I looking at?”
So, if you’re still struggling, we’ve edited the picture slightly to make the face a little clearer:
That any better? (X)
OK, let’s put you sharp-sighted folks out of your misery – you should be able to spot a spooky-looking woman with a pale white face and dark eyes glaring back at you from the left of the picture.
She’s hidden in the hair and body of the blonde girl and is admittedly easier to spot once you know she’s there – though that doesn’t make her any less creepy.
The side of the blonde girl’s face forms the forehead, while a shadow in her hair and under her chin forms the woman’s eyes. Towards the bottom of the hair is the nose, and a crease in the girl’s t-shirt forms the mouth.
So, now that you know it’s there, you’ll also know that you probably could have lived without seeing that eerie, lifeless face, couldn’t you?
Microsoft confirms critical Windows Defender vulnerability
Microsoft has confirmed that a critical-rated security vulnerability that impacted Windows Defender and could allow the improper authorization of an index containing sensitive information from a global files search would allow an attacker to disclose that data over a network. Yet, Microsoft said, Windows users needed to take no action—so, what’s going on?
Microsoft Windows Defender CVE-2024-49071 Vulnerability Confirmed
A Dec. 12 posting to Microsoft’s security update guide has confirmed that a Windows Defender vulnerability, rated as critical according to Microsoft itself, could have enabled an attacker who successfully exploited the issue to leak file content across a network.
According to the Debricked vulnerability database, CVE-2024-49071 the issue arose because Windows Defender created a “search index of private or sensitive documents,” but it did not “properly limit index access to actors who are authorized to see the original information.”
Why Windows Defender Users Are Advised No Action Is Necessary
You might think it odd that Microsoft’s advice to concerned users is that they need do nothing concerning this critical vulnerability impacting Windows Defender file content integrity. However, there is security method to this apparent madness. Yes, the issue has been fixed by Microsoft, but not by releasing an update that end users need to install. It has all been fixed behind the scenes at the server end of the equation.
As part of a new move towards more transparency when it comes to revealing server-side security vulnerabilities, announced by Microsoft’s security response team back in June, 2024, this is a notification for users rather than a call to action. “We will issue CVEs for critical cloud service vulnerabilities,” Microsoft said, “regardless of whether customers need to install a patch or to take other actions to protect themselves.”
And that is the case here: “The vulnerability documented by this CVE requires no customer action to resolve,” Microsoft said, “this vulnerability has already been fully mitigated by Microsoft.” So, there we have it. A critical Windows Defender vulnerability fixed quietly in the background, but with full transparency from Microsoft. Now that’s what good security looks like.
Apple Intelligence features may be landing on your iPhone, but that doesn’t mean they’ll stay fixed in place once they get there. Because they’re powered by artificial intelligence, Apple Intelligence capabilities have the potential to get smarter as Apple refines its models. And there’s always the possibility of Apple expanding what already-launched features can do.
The latter happened to Writing Tools with the iOS 18.2 update. Writing Tools arrived among the first batch of Apple Intelligence features in October’s iOS 18.1 release with the promise of improving your writing. Besides checking spelling and grammar, Writing Tools could also make suggestions on tone with presets that allow you to make any text you’ve written more professional, friendly or concise. There’s also a Rewrite option in Writing Tools for making wholesale changes to your document.
In my updated iOS 18 review, I wasn’t terribly complimentary toward Writing Tools. Aside from the Professional preset, which does a good job of observing the formal rules and structure that are a part of formal writing, the other options seemed to be satisfied with swapping in a few synonyms and sanding off any hint of writing voice. The end result usually resulted in robotic text — quite the opposite of what I think we should strive for in writing.
(Image credit: Future)
iOS 18.2 expands the arsenal of commands at Writing Tools’ disposal with a new Describe Your Change feature. Instead of relying on the presets, you can type out a text command like “make this more academic” or “make this sound more fun.” The idea seems to be to give you more control over the changes the AI makes to your writing.
Does the addition of Describe Your Change make me reassess the value of Writing Tools? And just how well does Apple Intelligence respond to your editing suggestions? I Took Describe Your Change for a test drive, and here’s what I found out.
How to use Describe Your Change in Writing Tools
(Image credit: Future)
Describe Your Change works like any other part of Writing Tools, which is available to any iOS app that accepts text input. Just select the text you’re looking to improve and Writing Tools will appear in the pop-up menu that also contains commands like Copy, Paste and whatnot. Some built-in apps like Notes will also feature an Apple Intelligence icon in their toolbar that summons Writing Tools.
Describe Your Change is now listed at the top of the Writing Tools menu that slides up from the bottom of the screen. It’s a text field that appears above the Proofread and Rewrite buttons. Just tap on the field and type in directions for Writing Tools. Tap the up arrow in the right side of the text field to put Writing Tools to rework at recasting your text.
How Describe Your Change performs
To see how well Describe Your Change follows instructions, I tried three different passages that I wrote in Notes. Two of the test documents were originals; the third was a well-known bit of dialogue from a movie. In addition to seeing if Describe Your Change delivered the changes I was looking for, I also checked to see if the AI tool improved my writing.
Test 1: Make this more enthusiastic
In my first sample text, I wrote a memo to members of my team that describes our next project — rolling a rock endlessly up a hill. Let me tell you, Sisyphus is getting the short end of the stick with this assignment, so I wanted to see if the Describe Your Change command could make my instructions a little livelier.
Text before using Describe Your Change (left) next to results from a “Make this more enthusiastic” command (right) (Image credit: Future)
While Writing Tools has apparently decided that exclamation marks indicate enthusiasm, I do have to admit that AI did a credible job of making the prospect of rolling a rock up a hill sound very exciting. A passage in the original text where I said I was “looking forward to great things and tangible results” became a section where I talked up “the amazing things and incredible results we’re going to achieve together.”
Writing Tools can lay it on a little thick, inserting a “How exciting is that?” right after I explained to Sisyphus that 50% of his bonus was tied to keeping the rock at the top of the hill. That interjection came across as not terribly sincere. But overall, you can’t fault Writing Tools for making my original text more enthusiastic. Sisyphus is now addressed as “the superstar tasked with getting that rock to the top of the hill,” and the memo now ends with a “Good luck, and let’s rock this project!” I like to think the pun was intentional.
Test 2: Make this more humble and earnest
I wanted to see how Writing Tools responded to a request with multiple instructions, so I took a letter to Santa Claus that I would best describe as “brusque” and “demanding” to see if the AI could make it sound a little more accommodating. I asked Writing Tools to pump up the humility and make the requests for presents seem a little less like expectations.
A Christmas letter to Santa (left) next to results from a “Make this more humble and earnest” command (right) (Image credit: Future)
For the most part, Writing Tools did a decent job making me sound less like an expectant brat. A passage where I asked for a PS5 or its cash equivalent went largely unchecked, but my assumption that Santa would obviously bring games to go with my PS5 had the rough edges sanded off. (“It would be wonderful to have some games to enjoy on it,” the AI-assisted me told Santa.)
The strongest element with Writing Tools’ pass through my letter was that it really emphasized my gratitude for any gift Santa brought. An assertion that I had been a very good boy who deserved presents became something less assuming: “I hope I’ve been a good boy, as I always strive to be. If my wishes could reflect that, I would be truly grateful.” The first part of that last sentence is phrased a little awkwardly, but at least Writing Tools captured the sentiment I had suggested.
Test 3: Make this friendlier
So far we’ve seen what Writing Tools and Describe Your Change can do with my writing. But what about Academy Award-winning screenwriter Aaron Sorkin? If you’ve seen the film adaptation of his “A Few Good Men” play, you doubtlessly remember the “You can’t handle the truth” speech that Jack Nicholson gives in the climactic courtroom scene. And if you’re like me, you probably wondered, “What if that Marine colonel had just been a little nicer?”
A Few Good Men speech (left) next to the results from a “Make this friendlier” command (right) (Image credit: Future)
So I took that speech, pasted it into Notes and told the Describe Your Change tool to “Make this friendlier” — a pretty tall task given the ferocity of Colonel Jessep’s words. And Writing Tools may have sensed it wasn’t up to the task, as I got a message warning me that the feature really wasn’t designed for this kind of writing. Nevertheless, I opted to continue, just for the purpose of testing the limits of Describe Your Change.
To give Writing Tools credit, it did make the passage friendly, but that involved some serious rewriting to the point where the original intent of the speech was lost to the four winds. “You don’t want the truth” became “Sometimes, the truth can be hard to accept.” But I think my favorite edit was to the closing line: “Either way, I don’t give a damn what you think you’re entitled to” became “Either way, I respect your perspective.” Friendlier, yes. What the author was going for, no.
Describe Your Change verdict
This new addition to Writing Tools only swung and missed on one of the three tests I threw its way, and in that instance, Writing Tools warned me that it was not really equipped to do what I was asking. In the other instances, Describe Your Change definitely struck the tone that I was looking for, and did so in a way that gave me finer control than the original presets in Writing Tools offered.
I think there are still limitations. One test I thought about including but eventually abandoned involved the passive voice — something a lot of writers struggle with. But asking Describe Your Change to “remove the passive voice” or “use active verbs” didn’t produce tangible results, leading me to conclude that’s not something the feature is really designed to do.
I’m not totally sold on Writing Tools yet. Even with the largely successful changes in tone, the AI still left behind some awkward sentences and phrases that didn’t always sound natural. Anyone using Writing Tools to check tone should still closely review any changes to make sure your intent hasn’t been drastically altered or that confusing word choice hasn’t been introduced to the text. And frankly, double-checking Writing Tools’ handiwork might take longer than just handling the editing yourself.
Still, it’s encouraging to see a tool I didn’t have much use for evolve from one iOS update to the next. Even if I never fully embrace Writing Tools it’s a positive sign for the rest of Apple Intelligence that Apple realizes there’s work still to be done to make its AI tools even better.
Scientists Urge Ban on ‘Mirror Life’ Before It Endangers Global Health
A league of scientists are calling for a critical discussion on the dangers of life forms made up of ‘mirror-image molecules’, because of the significant risks these creations may pose to global health.
These uncanny organisms are not yet a reality, but the authors think we need to take a long hard look in the mirror before stepping through it.
“Driven by curiosity and plausible applications, some researchers had begun work toward creating life forms composed entirely of mirror-image biological molecules,” the 38 experts write in a Science commentary.
“Such mirror organisms would constitute a radical departure from known life, and their creation warrants careful consideration.”
All life as we know it arises from ‘right-handed’ nucleotides in our DNA and RNA, and ‘left-handed’ amino acids that come together to form proteins.
This phenomenon is called homochirality. We don’t know for sure why it exists, but this defining feature of our biosphere’s chemical reactions leaves no room for alternatives.
To add to the confusion, mirror-image alternatives to our amino acids and nucleotides do exist. Which has led some researchers to ponder whether a new kind of life based on these flipped molecules could be created.
Such a feat would start small, with something like a bacteria.
There are a few reasons researchers are interested in creating these bizarro bacteria. Producing molecules from scratch is a laborious process that pharmaceutical companies would rather outsource to bacteria, but to produce mirror-image molecules, they need mirror-image microbes.
In 2016, Harvard geneticist George Church was part of a team that created a mirror version of DNA polymerase, the molecule that coordinates the copying and transcription of DNA into RNA.
Back then, Church was enthusiastic about the advance, describing it as a “terrific milestone” that would one day bring him closer to creating an entire mirror-image cell.
ScienceAlert
Now he is among the 38 scientists who are warning against it.
A cellular enzyme known as T7 RNA polymerase (left) helps build the RNA component of the protein-building factories known as ribosomes. Scientists created a mirror-image form (right) that could ultimately help create similarly flipped proteins. (Xu & Zhu, Science, 2022)
The fact that the body can’t break down these mirror-version proteins was initially considered a selling point, but that incompatibility with ‘natural’ life is also what now has scientists concerned.
“There is a plausible threat that mirror life could replicate unchecked, because it would be unlikely to be controlled by any of the natural mechanisms that prevent bacteria from overgrowing,” explains biochemist Michael Kay from the University of Utah.
“These are things like predators of the bacteria that help to keep it under control, antibiotics and the immune system, which are not expected to work on a mirror organism, and digestive enzymes.”
This back-to-front life form may be limited by its own organic incompatibility. Our molecular chirality makes us compatible with the molecular makeup of the organisms we break down for food, and it’s quite likely that mirror bacteria would struggle to survive without food that reflects its own makeup.
But the dozens of scientists behind the new paper agree that we cannot afford to play with such unknowns, even though the threat is far from imminent.
“It would require enormous effort to build such an organism,” says Vaughn Cooper, a microbiologist from the University of Pittsburg. “But we must stop that progress and have an organized, inclusive dialogue about how to effectively govern this.
“There is some exciting science that will be born because of these technologies that we want to facilitate. We don’t want to limit that promise of synthetic biology, but building a mirror bacterium is not worth the risk.”
The paper is published in Science, with an accompanying technical report published by Stanford University.
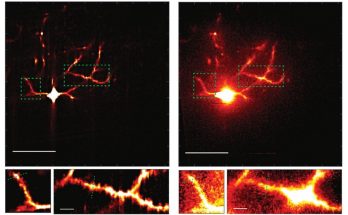
A newly described technology improves the clarity and speed of using two-photon microscopy to image synapses in the living brain.
Caption:
Left: A neuron imaged with multiline orthogonal scanning temporal focusing (mosTF). Right: The same neuron imaged with line-scanning temporal focusing microscope (lineTF). Below are magnifications of the dotted areas. In the mosTF images dendritic spines are clearly visible in the magnified images, while they are obscured by noise in the lineTF image.
Credits:
Images courtesy of Yi Xue, et. al.
The brain’s ability to learn comes from “plasticity,” in which neurons constantly edit and remodel the tiny connections called synapses that they make with other neurons to form circuits. To study plasticity, neuroscientists seek to track it at high resolution across whole cells, but plasticity doesn’t wait for slow microscopes to keep pace, and brain tissue is notorious for scattering light and making images fuzzy. In an open access paper in Scientific Reports, a collaboration of MIT engineers and neuroscientists describes a new microscopy system designed for fast, clear, and frequent imaging of the living brain.
The system, called “multiline orthogonal scanning temporal focusing” (mosTF), works by scanning brain tissue with lines of light in perpendicular directions. As with other live brain imaging systems that rely on “two-photon microscopy,” this scanning light “excites” photon emission from brain cells that have been engineered to fluoresce when stimulated. The new system proved in the team’s tests to be eight times faster than a two-photon scope that goes point by point, and proved to have a four-fold better signal-to-background ratio (a measure of the resulting image clarity) than a two-photon system that just scans in one direction.
“Tracking rapid changes in circuit structure in the context of the living brain remains a challenge,” says co-author Elly Nedivi, the William R. (1964) and Linda R. Young Professor of Neuroscience in The Picower Institute for Learning and Memory and MIT’s departments of Biology and Brain and Cognitive Sciences. “While two-photon microscopy is the only method that allows high-resolution visualization of synapses deep in scattering tissue, such as the brain, the required point-by-point scanning is mechanically slow. The mosTF system significantly reduces scan time without sacrificing resolution.”
Scanning a whole line of a sample is inherently faster than just scanning one point at a time, but it kicks up a lot of scattering. To manage that scattering, some scope systems just discard scattered photons as noise, but then they are lost, says lead author Yi Xue SM ’15, PhD ’19, an assistant professor at the University of California at Davis and a former graduate student in the lab of corresponding author Peter T.C. So, professor of mechanical engineering and biological engineering at MIT. Newer single-line and the mosTF systems produce a stronger signal (thereby resolving smaller and fainter features of stimulated neurons) by algorithmically reassigning scattered photons back to their origin. In a two-dimensional image, that process is better accomplished by using the information produced by a two-dimensional, perpendicular-direction system such as mosTF, than by a one-dimensional, single-direction system, Xue says.
“Our excitation light is a line, rather than a point — more like a light tube than a light bulb — but the reconstruction process can only reassign photons to the excitation line and cannot handle scattering within the line,” Xue explains. “Therefore, scattering correction is only performed along one dimension for a 2D image. To correct scattering in both dimensions, we need to scan the sample and correct scattering along the other dimension as well, resulting in an orthogonal scanning strategy.”
In the study the team tested their system head-to-head against a point-by-point scope (a two-photon laser scanning microscope — TPLSM) and a line-scanning temporal focusing microscope (lineTF). They imaged fluorescent beads through water and through a lipid-infused solution that better simulates the kind of scattering that arises in biological tissue. In the lipid solution, mosTF produced images with a 36-times better signal-to-background ratio than lineTF.
For a more definitive proof, Xue worked with Josiah Boivin in the Nedivi lab to image neurons in the brain of a live, anesthetized mouse, using mosTF. Even in this much more complex environment, where the pulsations of blood vessels and the movement of breathing provide additional confounds, the mosTF scope still achieved a four-fold better signal-to-background ratio. Importantly, it was able to reveal the features where many synapses dwell: the spines that protrude along the vine-like processes, or dendrites, that grow out of the neuron cell body. Monitoring plasticity requires being able to watch those spines grow, shrink, come, and go across the entire cell, Nedivi says.
“Our continued collaboration with the So lab and their expertise with microscope development has enabled in vivo studies that are unapproachable using conventional, out-of-the-box two-photon microscopes,” she adds.
So says he is already planning further improvements to the technology.
“We’re continuing to work toward the goal of developing even more efficient microscopes to look at plasticity even more efficiently,” he says. “The speed of mosTF is still limited by needing to use high-sensitivity, low-noise cameras that are often slow. We are now working on a next-generation system with new type of detectors such as hybrid photomultiplier or avalanche photodiode arrays that are both sensitive and fast.”
In addition to Xue, So, Boivin, and Nedivi, the paper’s other authors are Dushan Wadduwage and Jong Kang Park.
The National Institutes of Health, Hamamatsu Corp., Samsung Advanced Institute of Technology, Singapore-MIT Alliance for Research and Technology Center, Biosystems and Micromechanics, The Picower Institute for Learning and Memory, The JPB Foundation, and The Center for Advanced Imaging at Harvard University provided support for the research.
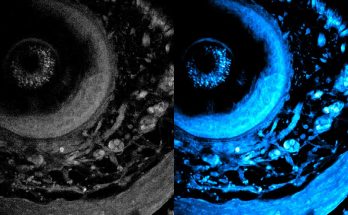
Using high-powered lasers, this new method could help biologists study the body’s immune responses and develop new medicines.
Caption:
The new technique enables laser light to penetrate deeper into living tissue, which captures sharper images of cells at different layers of a living system. On left is the initial image, and on right is the optimized image using the new technique.
Credits:
Credit: Courtesy of the researchers
Metabolic imaging is a noninvasive method that enables clinicians and scientists to study living cells using laser light, which can help them assess disease progression and treatment responses.
But light scatters when it shines into biological tissue, limiting how deep it can penetrate and hampering the resolution of captured images.
Now, MIT researchers have developed a new technique that more than doubles the usual depth limit of metabolic imaging. Their method also boosts imaging speeds, yielding richer and more detailed images.
This new technique does not require tissue to be preprocessed, such as by cutting it or staining it with dyes. Instead, a specialized laser illuminates deep into the tissue, causing certain intrinsic molecules within the cells and tissues to emit light. This eliminates the need to alter the tissue, providing a more natural and accurate representation of its structure and function.
The researchers achieved this by adaptively customizing the laser light for deep tissues. Using a recently developed fiber shaper — a device they control by bending it — they can tune the color and pulses of light to minimize scattering and maximize the signal as the light travels deeper into the tissue. This allows them to see much further into living tissue and capture clearer images.
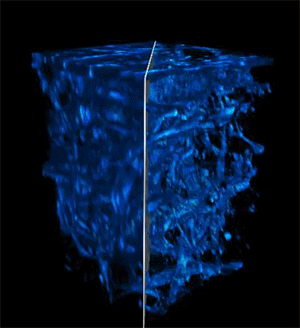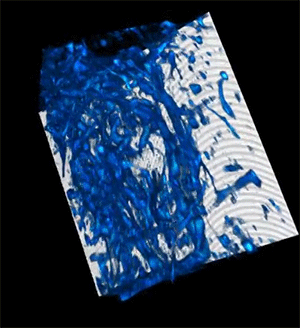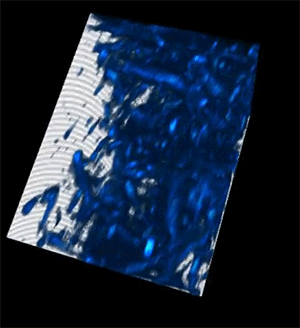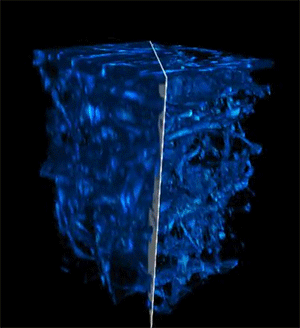
This animation shows deep metabolic imaging of living intact 3D multicellular systems, which were grown in the Roger Kamm lab at MIT. The clearer side is the result of the researchers’ new imaging method, in combination with their previous work on physics-based deblurring.Credit: Courtesy of the researchers
Greater penetration depth, faster speeds, and higher resolution make this method particularly well-suited for demanding imaging applications like cancer research, tissue engineering, drug discovery, and the study of immune responses.
“This work shows a significant improvement in terms of depth penetration for label-free metabolic imaging. It opens new avenues for studying and exploring metabolic dynamics deep in living biosystems,” says Sixian You, assistant professor in the Department of Electrical Engineering and Computer Science (EECS), a member of the Research Laboratory for Electronics, and senior author of a paper on this imaging technique.
She is joined on the paper by lead author Kunzan Liu, an EECS graduate student; Tong Qiu, an MIT postdoc; Honghao Cao, an EECS graduate student; Fan Wang, professor of brain and cognitive sciences; Roger Kamm, the Cecil and Ida Green Distinguished Professor of Biological and Mechanical Engineering; Linda Griffith, the School of Engineering Professor of Teaching Innovation in the Department of Biological Engineering; and other MIT colleagues. The research appears today in Science Advances.
Laser-focused
This new method falls in the category of label-free imaging, which means tissue is not stained beforehand. Staining creates contrast that helps a clinical biologist see cell nuclei and proteins better. But staining typically requires the biologist to section and slice the sample, a process that often kills the tissue and makes it impossible to study dynamic processes in living cells.
In label-free imaging techniques, researchers use lasers to illuminate specific molecules within cells, causing them to emit light of different colors that reveal various molecular contents and cellular structures. However, generating the ideal laser light with certain wavelengths and high-quality pulses for deep-tissue imaging has been challenging.
The researchers developed a new approach to overcome this limitation. They use a multimode fiber, a type of optical fiber which can carry a significant amount of power, and couple it with a compact device called a “fiber shaper.” This shaper allows them to precisely modulate the light propagation by adaptively changing the shape of the fiber. Bending the fiber changes the color and intensity of the laser.
Building on prior work, the researchers adapted the first version of the fiber shaper for deeper multimodal metabolic imaging.
“We want to channel all this energy into the colors we need with the pulse properties we require. This gives us higher generation efficiency and a clearer image, even deep within tissues,” says Cao.
Once they had built the controllable mechanism, they developed an imaging platform to leverage the powerful laser source to generate longer wavelengths of light, which are crucial for deeper penetration into biological tissues.
“We believe this technology has the potential to significantly advance biological research. By making it affordable and accessible to biology labs, we hope to empower scientists with a powerful tool for discovery,” Liu says.
Dynamic applications
When the researchers tested their imaging device, the light was able to penetrate more than 700 micrometers into a biological sample, whereas the best prior techniques could only reach about 200 micrometers.
“With this new type of deep imaging, we want to look at biological samples and see something we have never seen before,” Liu adds.
The deep imaging technique enabled them to see cells at multiple levels within a living system, which could help researchers study metabolic changes that happen at different depths. In addition, the faster imaging speed allows them to gather more detailed information on how a cell’s metabolism affects the speed and direction of its movements.
This new imaging method could offer a boost to the study of organoids, which are engineered cells that can grow to mimic the structure and function of organs. Researchers in the Kamm and Griffith labs pioneer the development of brain and endometrial organoids that can grow like organs for disease and treatment assessment.
However, it has been challenging to precisely observe internal developments without cutting or staining the tissue, which kills the sample.
This new imaging technique allows researchers to noninvasively monitor the metabolic states inside a living organoid while it continues to grow.
With these and other biomedical applications in mind, the researchers plan to aim for even higher-resolution images. At the same time, they are working to create low-noise laser sources, which could enable deeper imaging with less light dosage.
They are also developing algorithms that react to the images to reconstruct the full 3D structures of biological samples in high resolution.
In the long run, they hope to apply this technique in the real world to help biologists monitor drug response in real-time to aid in the development of new medicines.
“By enabling multimodal metabolic imaging that reaches deeper into tissues, we’re providing scientists with an unprecedented ability to observe nontransparent biological systems in their natural state. We’re excited to collaborate with clinicians, biologists, and bioengineers to push the boundaries of this technology and turn these insights into real-world medical breakthroughs,” You says.
“This work is exciting because it uses innovative feedback methods to image cell metabolism deeper in tissues compared to current techniques. These technologies also provide fast imaging speeds, which was used to uncover unique metabolic dynamics of immune cell motility within blood vessels. I expect that these imaging tools will be instrumental for discovering links between cell function and metabolism within dynamic living systems,” says Melissa Skala, an investigator at the Morgridge Institute for Research who was not involved with this work.
“Being able to acquire high resolution multi-photon images relying on NAD(P)H autofluorescence contrast faster and deeper into tissues opens the door to the study of a wide range of important problems,” adds Irene Georgakoudi, a professor of biomedical engineering at Tufts University who was also not involved with this work. “Imaging living tissues as fast as possible whenever you assess metabolic function is always a huge advantage in terms of ensuring the physiological relevance of the data, sampling a meaningful tissue volume, or monitoring fast changes. For applications in cancer diagnosis or in neuroscience, imaging deeper — and faster — enables us to consider a richer set of problems and interactions that haven’t been studied in living tissues before.”
This research is funded, in part, by MIT startup funds, a U.S. National Science Foundation CAREER Award, an MIT Irwin Jacobs and Joan Klein Presidential Fellowship, and an MIT Kailath Fellowship.
Medical inflation has outpaced overall inflation since 2000
A recent survey suggests claims denials are increasing
20 million people owe more than $220 billion in medical debt
$100 bill with medical mask. (Getty Images/Stock Photo)
(NewsNation) — Rising medical costs and denied claims have many Americans feeling fed up with the nation’s health care system.
The data paints a gloomy picture: The U.S. spends significantly more on health care than other countries (and yet has worse outcomes), insurance costs are rising and millions of people are buried in medical debt.
Those statistics underpin a mounting frustration that recently boiled over following the murder of UnitedHealthcare CEO Brian Thompson. Instead of condemning the brazen attack, many celebrated.
Health insurance stocks have fallen since UnitedHealthcare CEO killing
The outpouring of rage aimed at health insurance companies follows a two-decade period in which medical prices have risen faster than overall inflation.
Since 2000, the price of medical care has increased by more than 120%, outpacing the 86% gain for all goods and services, according to the Peterson Center on Healthcare and Kaiser Family Foundation (KFF).
Over the same period, health care conglomerates including UnitedHealth Group and Cigna Group have seen their stocks surge.
Health insurance premiums have risen
In 2024, the average health insurance premium for families hit $25,572 a year, up 7% for the second year in a row, according to KFF.
Of that total, workers contributed an average of $6,296 while employers contributed $19,276.
KFF pointed out that employers have borne much of the premium hike in recent years while workers’ annual premiums are up less than $300, about 5%, since 2019.
But higher deductibles have many families paying more out of pocket before their insurance kicks in. Once rare, high-deductible health plans have become increasingly popular as workers look to minimize their monthly premiums.
The percentage of workers enrolled in high deductible plans skyrocketed from 4% in 2006 to 29% in 2023, KFF data shows.
A recent Gallup poll found nearly 80% of Americans are dissatisfied with the cost of health care and most (54%) think the nation’s health care system has “major problems.”
A new report from the Government Accountability Office (GAO) suggests health insurance costs will likely rise again in 2025. In part, due to growing market concentration among fewer insurance companies.
How common are denied claims?
Nearly one in five insured adults (18%) said they experienced a denied claim in the past year, according to a KFF survey. The problem was more common among people with employer-sponsored insurance (21%) compared to people with Medicare (10%) or Medicaid (12%).
A separate KFF analysis found that major medical insurers offering plans via the Healthcare.gov marketplace rejected nearly one in dicw in-network claims in 2021.
However, denial rates varied significantly across plan issuers, ranging from 2% to 49%. In total, HealthCare.gov issuers denied 48.3 million in-network claims in 2021, KFF found.
A recent survey from credit firm Experian suggests denials of health claims are increasing, rising 31% in 2024 from 2022.
Of the health care staff Experian surveyed, 73% of providers agreed that claim denials are increasing.
In a first, researchers have shown that adding more “qubits” to a quantum computer can make it more resilient. It’s an essential step on the long road to practical applications.
Introduction
How do you construct a perfect machine out of imperfect parts? That’s the central challenge for researchers building quantum computers. The trouble is that their elementary building blocks, called qubits, are exceedingly sensitive to disturbance from the outside world. Today’s prototype quantum computers are too error-prone to do anything useful.
In the 1990s, researchers worked out the theoretical foundations for a way to overcome these errors, called quantum error correction. The key idea was to coax a cluster of physical qubits to work together as a single high-quality “logical qubit.” The computer would then use many such logical qubits to perform calculations. They’d make that perfect machine by transmuting many faulty components into fewer reliable ones.
“That’s really the only path that we know of toward building a large-scale quantum computer,” said Michael Newman(opens a new tab), an error-correction researcher at Google Quantum AI.
This computational alchemy has its limits. If the physical qubits are too failure-prone, error correction is counterproductive — adding more physical qubits will make the logical qubits worse, not better. But if the error rate goes below a specific threshold, the balance tips: The more physical qubits you add, the more resilient each logical qubit becomes.
Now, in a paper(opens a new tab) published today in Nature, Newman and his colleagues at Google Quantum AI have finally crossed the threshold. They transformed a group of physical qubits into a single logical qubit, then showed that as they added more physical qubits to the group, the logical qubit’s error rate dropped sharply.
A Google Quantum AI researcher works on Google’s superconducting quantum computer.
Google Quantum AI
“The whole story hinges on that kind of scaling,” said David Hayes(opens a new tab), a physicist at the quantum computing company Quantinuum. “It’s really exciting to see that become a reality.”
Majority Rules
The simplest version of error correction works on ordinary “classical” computers, which represent information as a string of bits, or 0s and 1s. Any random glitch that flips the value of a bit will cause an error.
You can guard against errors by spreading information across multiple bits. The most basic approach is to rewrite each 0 as 000 and each 1 as 111. Any time the three bits in a group don’t all have the same value, you’ll know an error has occurred, and a majority vote will fix the faulty bit.
But the procedure doesn’t always work. If two bits in any triplet simultaneously suffer errors, the majority vote will return the wrong answer.
To avoid this, you could increase the number of bits in each group. A five-bit version of this “repetition code,” for example, can tolerate two errors per group. But while this larger code can handle more errors, you’ve also introduced more ways things can go wrong. The net effect is only beneficial if each individual bit’s error rate is below a specific threshold. If it’s not, then adding more bits only makes your error problem worse.
As usual, in the quantum world, the situation is trickier. Qubits are prone to more kinds of errors than their classical cousins. It’s also much harder to manipulate them. Every step in a quantum computation is another source of error, as is the error-correction procedure itself. What’s more, there’s no way to measure the state of a qubit without irreversibly disturbing it — you must somehow diagnose errors without ever directly observing them. All of this means that quantum information must be handled with extreme care.
“It’s intrinsically more delicate,” said John Preskill(opens a new tab), a quantum physicist at the California Institute of Technology. “You have to worry about everything that can go wrong.”
At first, many researchers thought quantum error correction would be impossible. They were proved wrong in the mid-1990s, when researchers devised simple examples of quantum error-correcting codes. But that only changed the prognosis from hopeless to daunting.
When researchers worked out the details, they realized they’d have to get the error rate for every operation on physical qubits below 0.01% — only one in 10,000 could go wrong. And that would just get them to the threshold. They would actually need to go well beyond that — otherwise, the logical qubits’ error rates would decrease excruciatingly slowly as more physical qubits were added, and error correction would never work in practice.
Nobody knew how to make a qubit anywhere near good enough. But as it turned out, those early codes only scratched the surface of what’s possible.
The Surface Code
In 1995, the Russian physicist Alexei Kitaev(opens a new tab) heard reports of a major theoretical breakthrough in quantum computing. The year before, the American applied mathematician Peter Shor had devised a quantum algorithm for breaking large numbers into their prime factors. Kitaev couldn’t get his hands on a copy of Shor’s paper, so he worked out his own version(opens a new tab) of the algorithm from scratch — one that turned out to be more versatile than Shor’s. Preskill was excited by the result and invited Kitaev to visit his group at Caltech.
“Alexei is really a genius,” Preskill said. “I’ve known very few people with that level of brilliance.”
That brief visit, in the spring of 1997, was extraordinarily productive. Kitaev told Preskill about two new ideas he’d been pursuing: a “topological” approach to quantum computing that wouldn’t need active error correction at all, and a quantum error-correcting code based on similar mathematics. At first, he didn’t think that code would be useful for quantum computations. Preskill was more bullish and convinced Kitaev that a slight variation(opens a new tab) of his original idea was worth pursuing.
That variation, called the surface code, is based on two overlapping grids of physical qubits. The ones in the first grid are “data” qubits. These collectively encode a single logical qubit. Those in the second are “measurement” qubits. These allow researchers to snoop for errors indirectly, without disturbing the computation.
This is a lot of qubits. But the surface code has other advantages. Its error-checking scheme is much simpler than those of competing quantum codes. It also only involves interactions between neighboring qubits — the feature that Preskill found so appealing.
In the years that followed, Kitaev, Preskill and a handful of colleagues fleshed out the details(opens a new tab) of the surface code. In 2006, two researchers showed(opens a new tab) that an optimized version of the code had an error threshold around 1%, 100 times higher than the thresholds of earlier quantum codes. These error rates were still out of reach for the rudimentary qubits of the mid-2000s, but they no longer seemed so unattainable.
Despite these advances, interest in the surface code remained confined to a small community of theorists — people who weren’t working with qubits in the lab. Their papers used an abstract mathematical framework foreign to the experimentalists who were.
“It was just really hard to understand what’s going on,” recalled John Martinis(opens a new tab), a physicist at the University of California, Santa Barbara who is one such experimentalist. “It was like me reading a string theory paper.”
In 2008, a theorist named Austin Fowler(opens a new tab) set out to change that by promoting the advantages of the surface code to experimentalists throughout the United States. After four years, he found a receptive audience in the Santa Barbara group led by Martinis. Fowler, Martinis and two other researchers wrote a 50-page paper(opens a new tab) that outlined a practical implementation of the surface code. They estimated that with enough clever engineering, they’d eventually be able to reduce the error rates of their physical qubits to 0.1%, far below the surface-code threshold. Then in principle they could scale up the size of the grid to reduce the error rate of the logical qubits to an arbitrarily low level. It was a blueprint for a full-scale quantum computer.
John Martinis (left) and Austin Fowler developed a blueprint for a quantum computer based on the surface code.
From left: Courtesy of John Martinis; Courtesy of Austin Fowler
Of course, building one wouldn’t be easy. Cursory estimates suggested that a practical application of Shor’s factoring algorithm would require trillions of operations. An uncorrected error in any one would spoil the whole thing. Because of this constraint, they needed to reduce the error rate of each logical qubit to well below one in a trillion. For that they’d need a huge grid of physical qubits. The Santa Barbara group’s early estimates suggested that each logical qubit might require thousands of physical qubits.
“That just scared everyone,” Martinis said. “It kind of scares me too.”
But Martinis and his colleagues pressed on regardless, publishing a proof-of-principle experiment(opens a new tab) using five qubits in 2014. The result caught the eye of an executive at Google, who soon recruited Martinis to lead an in-house quantum computing research group. Before trying to wrangle thousands of qubits at once, they’d have to get the surface code working on a smaller scale. It would take a decade of painstaking experimental work to get there.
Crossing the Threshold
When you put the theory of quantum computing into practice, the first step is perhaps the most consequential: What hardware do you use? Many different physical systems can serve as qubits, and each has different strengths and weaknesses. Martinis and his colleagues specialized in so-called superconducting qubits, which are tiny electrical circuits made of superconducting metal on silicon chips. A single chip can host many qubits arranged in a grid — precisely the layout the surface code demands.
The Google Quantum AI team spent years improving their qubit design and fabrication procedures, scaling up from a handful of qubits to dozens, and honing their ability to manipulate many qubits at once. In 2021, they were finally ready to try error correction with the surface code for the first time. They knew they could build individual physical qubits with error rates below the surface-code threshold. But they had to see if those qubits could work together to make a logical qubit that was better than the sum of its parts. Specifically, they needed to show that as they scaled up the code — by using a larger patch of the physical-qubit grid to encode the logical qubit — the error rate would get lower.
They started with the smallest possible surface code, called a “distance-3” code, which uses a 3-by-3 grid of physical qubits to encode one logical qubit (plus another eight qubits for measurement, for a total of 17). Then they took one step up, to a distance-5 surface code, which has 49 total qubits. (Only odd code distances are useful.)
Mark Belan/Quanta Magazine
In a 2023 paper(opens a new tab), the team reported that the error rate of the distance-5 code was ever so slightly lower than that of the distance-3 code. It was an encouraging result, but inconclusive — they couldn’t declare victory just yet. And on a practical level, if each step up only reduces the error rate by a smidgen, scaling won’t be feasible. To make progress, they would need better qubits.
The team devoted the rest of 2023 to another round of hardware improvements. At the beginning of 2024, they had a brand-new 72-qubit chip, code-named Willow, to test out. They spent a few weeks setting up all the equipment needed to measure and manipulate qubits. Then in February, they started collecting data. A dozen researchers crowded into a conference room to watch the first results come in.
“No one was sure what was going to happen,” said Kevin Satzinger(opens a new tab), a physicist at Google Quantum AI who co-led the effort with Newman. “There are a lot of details in getting these experiments to work.”
Then a graph popped up on the screen. The error rate for the distance-5 code wasn’t marginally lower than that of the distance-3 code. It was down by 40%. Over the following months, the team improved that number to 50%: One step up in code distance cut the logical qubit’s error rate in half.
“That was an extremely exciting time,” Satzinger said. “There was kind of an electric atmosphere in the lab.”
The team also wanted to see what would happen when they continued to scale up. But a distance-7 code would need 97 total qubits, more than the total number on their chip. In August, a new batch of 105-qubit Willow chips came out, but by then the team was approaching a hard deadline — the testing cycle for the next round of design improvements was about to begin. Satzinger began to make peace with the idea that they wouldn’t have time to run those final experiments.
“I was sort of mentally letting go of distance-7,” he said. Then, the night before the deadline, two new team members, Gabrielle Roberts and Alec Eickbusch, stayed up until 3 a.m. to get everything working well enough to collect data. When the group returned the following morning, they saw that going from a distance-5 to a distance-7 code had once again cut the logical qubit’s error rate in half. This kind of exponential scaling — where the error rate drops by the same factor with each step up in code distance — is precisely what the theory predicts. It was an unambiguous sign that they’d reduced the physical qubits’ error rates well below the surface-code threshold.
“There’s a difference between believing in something and seeing it work,” Newman said. “That was the first time where I was like, ‘Oh, this is really going to work.’”
The Long Road Ahead
The result has also thrilled other quantum computing researchers.
“I think it’s amazing,” said Barbara Terhal(opens a new tab), a theoretical physicist at the Delft University of Technology. “I didn’t actually expect that they would fly through the threshold like this.”
At the same time, researchers recognize that they still have a long way to go. The Google Quantum AI team only demonstrated error correction using a single logical qubit. Adding interactions between multiple logical qubits will introduce new experimental challenges.
Then there’s the matter of scaling up. To get the error rates low enough to do useful quantum computations, researchers will need to further improve their physical qubits. They’ll also need to make logical qubits out of something much larger than a distance-7 code. Finally, they’ll need to combine thousands of these logical qubits — more than a million physical qubits.
Meanwhile, other researchers have made impressive(opens a new tab) advances(opens a new tab) using different qubit technologies, though they haven’t yet shown that they can reduce error rates by scaling up. These alternative technologies may have an easier time implementing new error-correcting codes that demand fewer physical qubits. Quantum computing is still in its infancy. It’s too early to say which approach will win out.
Martinis, who left Google Quantum AI in 2020, remains optimistic despite the many challenges. “I lived through going from a handful of transistors to billions,” he said. “Given enough time, if we’re clever enough, we could do that.”
Representation of the the Universe’s expansion.(NASA)
In case dark matter didn’t seem mysterious enough, a new study proposes that it could have arisen before the Big Bang.
Conventional thinking goes that the Big Bang was the beginning of everything – matter, dark matter, space, energy, all of it. After the event itself, the Universe went through a period of cosmic inflation, which saw its size swell by a factor of 10 septillion within an unfathomable fraction of a second.
But some theories suggest that this inflation period actually occurred before what we call the Big Bang. And now, physicists at the University of Texas (UT) at Austin have proposed that dark matter was formed during this brief window.
The team calls the new model warm inflation via freeze-in, or WIFI. Basically, dark matter particles would be created from tiny interactions between radiation and particles in a warm ‘thermal bath’ during the inflation period.
“The thing that’s unique to our model is that dark matter is successfully produced during inflation,” says Katherine Freese, a theoretical astrophysicist at UT Austin.
“In most models, anything that is created during inflation is then ‘inflated away’ by the exponential expansion of the Universe, to the point where there is essentially nothing left.”
It’s thought that prior to the Big Bang, the entirety of the Universe existed in a singularity, a point of infinite density where spacetime is infinitely curved. But the known laws of physics completely break down there, so some physicists propose that a different epoch preceded the Big Bang, instead of a singularity.
This could be the collapse of an earlier universe, as in the Big Bounce model – or it could be cosmic inflation. This phase lasted just nonillionths of a second, and the energy transferred to matter and light to become what we refer to as the Big Bang.
From there, the stage is set for the Universe to evolve as described by general relativity.
The authors of the new study aren’t the first to suggest that cosmic inflation predated the Big Bang. They aren’t even the first to suggest that dark matter arose during this epoch. What is new is their mechanism for how the strange stuff is produced, in quantities that align with astronomical observations.
Warm inflation (the ‘WI’ in the new WIFI model) is an existing idea that suggests that radiation is produced while the exponential expansion is taking place. This creates a kind of thermal bath, allowing for tiny but important interactions to occur.
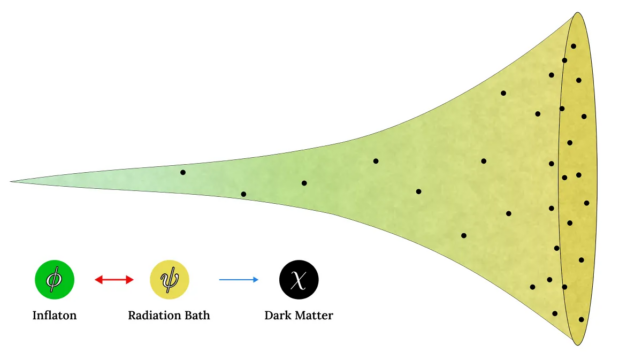
A diagram illustrating how interactions between inflatons (green) and radiation in the thermal bath (yellow) produce dark matter (black dots). (Gabriele Montefalcone)
The driver of cosmic inflation is still unknown, but the stand-in is a field of hypothetical particles called inflatons, similar to the famous Higgs boson. In the warm inflation scenario, this inflaton field would lose some of its energy to radiation in the thermal bath.
From there, the radiation produces dark matter particles through a process called UV freeze-in (there’s the ‘FI’ in WIFI). Essentially, the dark matter never reaches equilibrium with the bath, and the temperature of that bath stays below a certain threshold.
According to the team’s calculations, this mechanism produces enough dark matter to account for the amount that astronomical observations tell us is out there.
This doesn’t mean the mystery is solved, of course. It’s just one hypothesis of many, including that dark matter arose in its own ‘Dark Big Bang’ later on.
For now, the WIFI model can’t be directly verified, but at least part of it could be soon. Upcoming studies of the cosmic microwave background, such as CMB-S4, could put the idea of warm inflation to the test.
“If future observations confirm that warm inflation is the correct paradigm, it would significantly strengthen the case for dark matter being produced as described in our framework,” says UT physicist Gabriele Montefalcone, co-author of the study.
The research was published in the journal Physical Review Letters.